CD: Community Detection
تشخیص انجمنCD: Community Detection
تشخیص انجمنروش توزیعی تشخیص انجمن در شبکه های اجتماعی بزرگ بر اساس انتشار برچسب
تشخیص انجمن های هم پوشان در شبکه های اجتماعی بسیار بزرگ با عامل های هوشمند یک مساله سخت و مهم است که قدرت تشخیص و تحلیل آن شبکه ها را از حالت بی درنگ برخط خارج می کند. همپوشانی انجمن ها در کنار افزایش ابعاد و ارتباطات این شبکه ها به چالش های پیچیدگی زمان زیاد جستجوی انجمن ها و افزایش طاقت فرسای حافظه مصرفی منجر می شود که از قابلیت کنترل سریع آن ها می کاهد. ارایه روش های توزیعی مقیاس پذیر تصادفی و عامل گرا, بر اساس انتشار برچسب در شبکه های بسیار بزرگ و پیچیده به کاهش زمان جستجو و تسریع تشخیص کمک می کند. این مقاله روش توزیعی نوین مقیاس پذیر عامل گرا برای تشخیص انجمن های هم پوشان بر اساس انتشار برچسب توانسته با محدودسازی انتشار پیام و استفاده از معیارهای جدید بر روی معماری چندهسته ای, به پیچیدگی خطی زمان اجرا و حافظه مصرفی دست یابد. روش پیشنهادی با آزمون بر روی مجموعه داده های بسیار بزرگ شبکه های اجتماعی, از نظر زمان اجرا در شبکه های بزرگ تا 9 برابر تسریع و از نظر پیمانه ای از %3 تا %100 بهبود دارد و در یافتن انجمن های هم پوشان بسیار دقیق و سریع عمل می کند.
لینک دانلود مقاله: روش توزیعی تشخیص انجمن در شبکه های اجتماعی بزرگ بر اساس انتشار برچسب

تفاوت association با Community
تفاوت اصلی بین مفهوم "association" و "community" در ارتباط با شبکهها یا گرافها به شرح زیر است:
Associationیا ارتباط: به رابطه و اتصال بین دو یا چند عنصر در یک شبکه یا ساختار گرافی اشاره دارد. این مفهوم به نحوهی ارتباط یا ارتباطات بین عناصر میپردازد، بدون ارائهی هرگونه تعریف خاصی از گروه یا جامعه.
Communityیا جامعه: به مجموعهای از عناصر درون یک شبکه یا گراف که با یکدیگر ارتباطات نزدیکی دارند و به صورت گستردهتر با یکدیگر ارتباط برقرار میکنند، اشاره دارد. این عناصر معمولاً درون یک گروه خاص مشخص میشوند و میتوانند با توجه به ویژگیهای مختلف مشترک، به عنوان یک جامعه یا انجمن تشخیص داده شوند
در کل associationبه رابطه و اتصال بین عناصر در یک شبکه اشاره دارد، در حالی که "community" به گروههای عناصر مشابه یا مرتبط درون یک شبکه میپردازد که ارتباطات نزدیکی با یکدیگر دارند و به صورت جامعهای در نظر گرفته میشوند.
بطور کلی association به ارتباطات و روابط میان عناصر یک شبکه یا گراف اشاره دارد. این ارتباطات ممکن است براساس معیارهای مختلفی مانند وابستگی، همبستگی یا تقارن بین دو یا چند عنصر تعریف شود. به عنوان مثال، ارتباطات بین کاربران در شبکههای اجتماعی مانند دنبال کردن یکدیگر، لایک کردن یا ارسال پیامها ممکن است نمونههایی از ارتباطات یاassociation باشند.
به عنوان مقابل، "community" یا "جامعه" به گروههایی از عناصر داخل یک شبکه یا گراف اشاره دارد که این عناصر به علت ویژگیهای مشترک یا روابط نزدیک با یکدیگر، به صورت یک واحد تشخیص داده میشوند. این گروهها یا انجمنها میتوانند با توجه به تحلیل شبکهای، خوشهبندی روابط، محتوای مشترک یا حتی نقشهای مشابه تشخیص داده شوند.
به عنوان مثال، در شبکههای اجتماعی، افرادی که با یکدیگر در ارتباطات نزدیکی هستند، نه تنها ممکن است association داشته باشند به عنوان مثال، دو نفر که یکدیگر را دنبال میکنند، بلکه ممکن است به عنوان یک انجمن یا جامعه در نظر گرفته شوند اگر ویژگیهای مشترک بیشتری نیز داشته باشند، مثلاً علایقیا فعالیتهای مشابه.
الگوریتم هایassociation
الگوریتمهایassociation معمولاً برای کشف الگوها، روابط و ارتباطات بین دادهها استفاده میشوند. این الگوریتمها به عنوان ابزارهایی برای کشف قوانینیا الگوهای مخفی در دادهها، مانند قوانین خریداری همزمان، تحلیل جریانهای کاربری، پیشبینی عملکرد و... عمل میکنند.
چندین الگوریتم برای کشف این ارتباطات و الگوها وجود دارد. برخی از معروفترین الگوریتمهایAssociation عبارتند از:
ادامه مطلب ...
الگوریتم DBSCAN
الگوریتم DBSCAN یا همان Density Based Spatial Clustering of Applications with Noise رایج ترین الگوریتم خوشه بندی مبتنی بر تراکم می باشد که در مقابل نویز و داده های پرت مقاوم می باشد. همچنین با توجه به ساختار این الگوریتم، جهت شناسایی الگوهای پیچیده و غیرکروی مورد استفاده قرار می گیرد.
ایده اصلی در این الگوریتم این است که یک رکورد به یک خوشه تعلق دارد در صورتی که به رکوردهای زیادی از آن خوشه نزدیک باشد.
بنابراین تعریف میزان تراکم داده ها، اهمیت اساسی در شناسایی ساختار الگوها دارد.
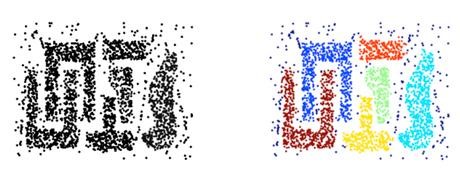
دو پارامتر اصلی برای اجرای الگوریتم
دو پارامتر اصلی برای اجرای الگوریتم وجود دارد:
eps یا شعاع همسایگی: فاصله ای که برای تعریف همسایگی به کار می رود. اگر دو رکورد دارای فاصله کمتر از آن باشند، نقاط همسایه در نظر گرفته می شود.
minPts: حداقل تعداد همسایه در محدوده یک شعاع تعریف شده جهت قرار گیری در یک خوشه با توجه به پارامترهای تعریف شده، سه گروه از داده ها قابل تعریف است:
نقاط مرکزی Core Point: نقاطی از داده ها که در شعاع همسایگی آنها حداقل به تعداد minPts همسایه وجود داشته باشد.
Border Points نقاط مرزی: همسایگانی از نقاط مرکزی که قابلیت تبدیل به نقاط مرکزی ندارند.
نقاط پرت Noise Points: نقاطی که در همسایگی هیچ نقطه مرکزی نیستند.