CD: Community Detection
تشخیص انجمنCD: Community Detection
تشخیص انجمنآموزش کتابخانه Pandas (پانداس)
Pandas از کتابخانههای متن بازی است که برای کار با دادههایی با ساختار رابطهای (rational) یا برچسبگذاری شده ایجاد شده است. این کتابخانه ساختار دادههای متنوعی به همراه امکان اعمال عملیات عددی روی این دادهها را فراهم میکند وبه خوبی میتواند با سریهای زمانی کار کند. Pandas بر مبنای کتابخانهی NumPy ساخته شده است و بسیاری از ساختارهای NumPy در این کتابخانه استفاده شده و گسترش یافتهاند. در ادامه به آموزش کتابخانه Pandas میپردازیم. مزایای این کتابخانه شامل موارد زیر است:
- سرعت و کارایی بالا در کار با دادهها.
- امکان بارگذاری دادهها از فایلهای متفاوت.
- کنترل راحت ویژگیهایی که مقداردهی نشدهاند. (به عبارتی این مقادیر با NaN مقداردهی شدهاند.)
- قابلیت تغییر اندازه: ستونهایی میتوانند به دادهها اضافه شوند و یا از آنها حذف شوند.
- ادغام (merge) و اتصال (join) مجموعه داده ها.
- تغییر شکل داده به طور منعطف.
- فراهم کردن امکان کار با سریهای زمانی.
- امکان گروهبندی دادهها با توجه به اهداف کاربردی.
- ساختار دادهها در کتابخانه Pandas
به طور کلی کتابخانه Pandas دارای دو دسته ساختار داده است:
- سری یا Series
- دیتافریم یا DataFrame
البته نوع سومی تحت عنوان Panel هم بود که در نسخههای جدید منسوخ شده است.
نوع دادهی Series
سری یک آرایهی یک بُعدی و برچسبگذاری شده است (دارای ایندکس برای سطرهاست) که میتواند انواع مختلف داده (عدد صحیح، اعشاری، رشته، آبجکتهای پایتون و...) را در خود نگه دارد.
به محور برچسبها اندیس یا index میگویند. سریهای کتابخانه Pandas مثل یک ستون از صفحهی اکسل است. اندیسها باید منحصر به فرد باشند و هر اندیس فقط به یک عنصر اشاره کند. منبع داده برای سریهای کتابخانه Pandas میتواند پایگاه دادهی SQL، فایلهای CSV و اکسل باشد. نوع دادهی ورودی سری نیز میتواند به شکل لیست، تاپل و دیکشنری و عدد اسکالر باشد.
ایجاد یک سری: یک سری در پانداس به شکل زیر تعریف میشود:
pandas.Series( data, index, dtype, copy)
که در آن:
- data: دادهی ورودی است که میتواند به شکل آرایه، لیست، دیکشنری یا عدد باشد.
- index: مقدار اندیس یا برچسب اختصاصی به هر سطر است که به طور پیشفرض از اعداد 0 تا n-1 است(n: تعداد دادههاست) و البته میتواند هر مقدار عددی یا رشتهای دلخواه را بگیرد.
- dtype: نوع دادهی اختصاصی به ستون داده است که اگر مقدار ندهیم، خودش از دادهها نوعشان را استنباط میکند.
- copy: کپی از سری ایجاد میکند و مقدار پیشفرض False دارد.
در مثال زیر نحوهی ایجاد یک سری با استفاده از آرایه را میبینیم.
import pandas as pd import numpy as np # Creating empty series ser = pd.Series() print(ser) # simple array data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser) Series([], dtype: float64) 0 g 1 e 2 e 3 k 4 s dtype: objectاگر مقدار ستون اندیس را مقداردهی نکنیم مانند مثال بالا به طور پیشفرض از صفر شروع به مقداردهی اندیسها میکند. میتوانیم ستون اندیسها را با عبارت index=[ ]نامگذاری کنیم:
pd.Series([1., 2., 3.], index=['a', 'b', 'c'])a 1.0 b 2.0 c 3.0 dtype: float64برای مشاهدهی دادههای یک سری از دستور values استفاده میکنیم و با index اندیسها را استخراج میکنیم:
my_series=pd.Series([1., 2., 3.], index=['a', 'b', 'c'])print(my_series.values)print(my_series.index)[1. 2. 3.] Index(['a', 'b', 'c'], dtype='object')دادهی ورودی یک سری میتواند به شکل دیکشنری نیز باشد. کلیدهای دیکشنری به طور پیشفرض در نقش ستون اندیسها ظاهر میشوند و اگر مقدار index به عنوان ورودی به کد داده شود، دادههای دیکشنری در مقابل اندیسهایی ظاهر میشوند که آن اندیس با مقدار کلید داده در دیکشنری برابر باشد.
import pandas as pdimport numpy as npdata = {'a' : 0., 'b' : 1., 'c' : 2.}s = pd.Series(data)print (s)سری خروجی به شکل زیر است:
a 0.0 b 1.0 c 2.0 dtype: float64میتوانیم ستون اندیس را خودمان مقدار دهی کنیم:
import pandas as pdimport numpy as npdata = {'a' : 0., 'b' : 1., 'c' : 2.}s = pd.Series(data,index=['b','c','d','a'])print (s)b 1.0 c 2.0 d NaN a 0.0 dtype: float64نکته: اگر داده به صورت دیکشنری باشد و اندیس سری را خودمان تعریف کنیم، آن اندیسی که در داخل کلیدهای دیکشنری نباشد مقدار NAN میگیرد. (مثل اندیس d در مثال بالا)
انتخاب و دستیابی به عناصر سری با مکان داده
میتوان به عناصر با شمارهی اندیس آنها و یا نام اندیس آنها در داخل براکت [ ] دسترسی داشت. در مثال زیر پنج عنصر اول را انتخاب میکنیم.
# import pandas and numpy import pandas as pdimport numpy as np# creating simple arraydata = np.array(['g','e','e','k','s','f', 'o','r','g','e','e','k','s'])ser = pd.Series(data)#retrieve the first elementprint(ser[:5])0 g1 e2 e3 k4 sdtype: objectدر مثال زیر هم به کمک برچسب اندیس به داده دسترسی داریم:
# import pandas and numpy import pandas as pdimport numpy as np# creating simple arraydata = np.array(['g','e','e','k','s','f', 'o','r','g','e','e','k','s'])ser = pd.Series(data,index=[10,11,12,13,14,15,16,17,18,19,20,21,22])# accessing a element using index elementprint(ser[16])o
اندیسدهی به داده میتواند به معنای انتخاب زیرمجموعهای از داده باشد. در مثال زیر ستونی با نام Name از یک فایل csv را انتخاب میکنیم و با تابع( head(10 به ده عنصر ابتدایی سری، دست مییابیم:
# importing pandas module import pandas as pd # making data frame df = pd.read_csv("nba.csv") ser = pd.Series(df['Name']) data = ser.head(10)data 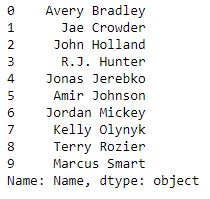
برای دستیابی به عناصر با اندیس 3 و 4 و 5 دستور زیر را مینویسیم:
# using indexing operatordata[3:6]
انتخاب عناصر سری با دستور loc
میتوان عدد یا برچسب اندیسهای مورد نظر را داخل براکت مقابل [loc[a:b قرار داد. توجه کنید که در اندیسدهی با loc، عدد آخر یعنی b درنظر گرفته میشود. به این مثال توجه کنید:
data.loc[3:6]
انتخاب عناصر سری با دستور iloc
دستور iloc مشابه loc است با این تفاوت که در [iloc[a:b اندیسها فقط باید عددی باشند و دادهی مربوط به اندیس عدد b نیز جزو عناصر انتخابی نخواهد بود، همانطور که در کد زیر مشاهده میکنید، عنصر با اندیس 6 جزو خروجی نیست:
# using .iloc[] functiondata.iloc[3:6]
اجرای عملیات باینری روی سریها
عملیات باینری مثل جمع و تفریق و ... را میتوان روی سریها انجام داد:
# importing pandas module import pandas as pd # creating a seriesdata = pd.Series([5, 2, 3,7], index=['a', 'b', 'c', 'd'])print(data)# creating a seriesdata1 = pd.Series([1, 6, 4, 9], index=['a', 'b', 'd', 'e'])print(data1)دو سری data و data1 را داریم:
a 5b 2c 3d 7dtype: int64a 1b 6d 4e 9dtype: int64حال برای جمع data و data1 از دستور add استفاده میکنیم:
data.add(data1, fill_value=0)
a 6.0b 8.0c 3.0d 11.0e 9.0dtype: float64سایر عملیات دودویی مثل .sub، .mul، .div،.pow و.... نیز وحود دارد که برای مطالعهی بیشتر میتوانید به داکیومنت کتابخانه Pandas مراجعه کنید.
دیتافریم (Dataframe) در کتابخانه Pandas
دیتافریم (Dataframe) یک ساختار دادهی دو بعُدی است و دادهها شامل سطر(یا همان index) و ستون (یا همان columns) است و ساختاری رابطهای است و هر تعداد داده میتوانیم در آن ذخیره کنیم و انواع عملیات محاسباتی و رابطهای را همچون انتخاب، اتصال و گروهبندی را روی آن انجام دهیم.
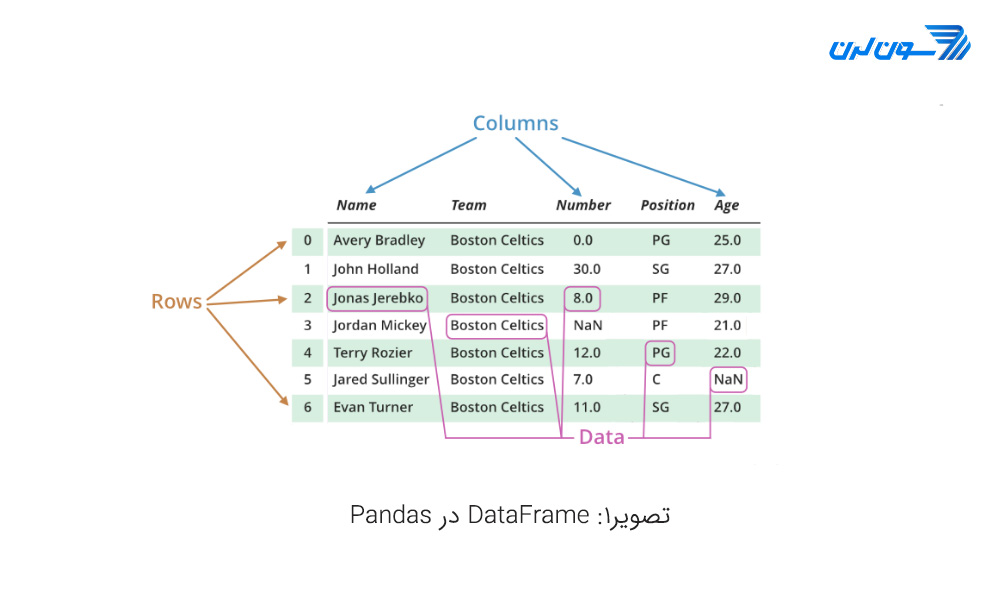
یک دیتافریم (Dataframe) در کتابخانه Pandas (پانداس) به شکل زیر تعریف میشود:
pandas.DataFrame( data, index, columns, dtype, copy)که در آن:
- data: دادهی ورودی است که میتواند لیست، آرایه، مقدار ثابت، دیکشنری و یا یک دیتافریم (Dataframe) باشد.
- index: برای برچسبدهی به سطرها استفاده میشود و اگر مقداری برایش تعریف نشود به طور خودکار از عدد 0 تا n-1 را که n تعداد دادههاست را، میگیرد.
- columns: برای برچسبدهی به ستونها استفاده میشود و اگر مقداری برایش تعریف نشود به طور خودکار از عدد 0 تا n-1 را که n تعداد ویژگی یا ستونهاست را، میگیرد.
- dtype: نوع ستونها را برمیگرداند.
- copy: اگر مقدارش True باشد از دادهها کپی ایجاد میکند، اما مقدار پیشفرض آن False است.
دیتافریم (Dataframe) در کتابخانه Pandas (پانداس)، به چند شکل مختلف میتواند ایجاد شود: 1.ایجاد دیتافریم (Dataframe) خالی یک دیتافریم (Dataframe) اولیه میتواند شامل هیچ مقداری نباشد و تنها با متد DataFrame آن را ایجاد کنیم:
# import pandas as pd import pandas as pd # Calling DataFrame constructor df = pd.DataFrame() print(df)Empty DataFrame Columns: [] Index: []2. ایجاد دیتافریم (Dataframe) با لیست دادهی دیتافریم (Dataframe) میتواند یک لیست یا لیستهای تودرتو باشد:
# import pandas as pd import pandas as pd # list of strings lst = ['this', 'is', 'a', 'practial', 'article', 'for', 'Pandas'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) print(df)
00 this1 is2 a3 practial4 article5 for6 Pandasنکته: پیش از ادامهی بقیهی مطالب، یادآور میشویم که در دیتافریم (Dataframe) هم مانند سریها میتوان ویژگی مرتبط با سطرها و ستونها را مقداردهی کرد.(مقادیر عددی یا رشتهای به index و columns داد.) اما اگر مقداردهی نکنیم به طور پیشفرض عددی و با شروع از صفر مقداردهی میشوند ((numpy.arrange(n :از 0 تا n-1). مثال زیر را ببینید:
# import pandas as pd import pandas as pd # list of strings lst = ['this', 'is', 'a', 'practical', 'article', 'for', 'Pandas'] # Calling DataFrame constructor on list df = pd.DataFrame(lst, index=['row1','row2','row3','row4','row5','row6','row7'], columns=['col1']) print(df) col1row1 thisrow2 isrow3 arow4 practicalrow5 articlerow6 forrow7 Pandas3- ایجاد دیتافریم (Dataframe) با دیکشنری
برای اینکه بتوانیم یک دیتافریم (Dataframe) با دادهای از جنس دیکشنری ایجاد کنیم که مقدار اختصاصی به هر کلید از نوع آرایه یا لیست است، باید طول این لیست یا آرایهها با هم برابر باشند. (اگر index را خودمان مقداردهی کنیم این مقدار باید برابر طول آرایه یا لیست باشد.). کلیدهای دیکشنری برای ستونهای دیتافریم (Dataframe) در نظر گرفته میشوند.
# Python code demonstrate creating # DataFrame from dict narray / lists # By default addresses. import pandas as pd # intialise data of lists. data = {'Name':['Tom', 'nick', 'krish', 'jack'], 'Age':[20, 21, 19, 18]} # Create DataFrame df = pd.DataFrame(data) # Print the output. print(df) خروجی این کد دیتافریمی (Dataframe) به شکل زیر است:
Name Age0 Tom 201 nick 212 krish 193 jack 18
کار با سطرها و ستونها در دیتافریم (Dataframe)
میتوان بر روی دیتافریم (Dataframe)ها عملیاتی چون انتخاب، حذف، افزودن و تغییر نام سطرها و ستونها را انجام داد.
انتخاب ستونها: برای انتخاب ستونها میتوان از نام آنها استفاده کرد. در کد زیر دیتافریمی (Dataframe) با نام df ایجاد میکنیم و سپس ستونهای Name و Qualification را انتخاب میکنیم.
# Import pandas packageimport pandas as pd# Define a dictionary containing employee datadata = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}# Convert the dictionary into DataFrame df = pd.DataFrame(data)# select two columnsprint(df[['Name', 'Qualification']])Name Qualification0 Jai Msc1 Princi MA2 Gaurav MCA3 Anuj Phd
انتخاب سطرها: سطرهای مورد نظر را میتوان با دستور loc یا iloc یا ix انتخاب کرد و البته همانطور که در قسمت Series گفته شد برای انتخاب سطر با iloc تنها از شمارهی برچسب اندیس میتوان استفاده کرد. دادههای زیر را در نظر بگیرید:
# Import pandas packageimport pandas as pd# Define a dictionary containing employee datadata = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}# Convert the dictionary into DataFrame df = pd.DataFrame(data,index=('Person1','Person2','Person3','Person4'))dfدیتافریم (Dataframe) ما در این کد به شکل زیر است:
| Name | Age | Address | Qualification | |
|---|---|---|---|---|
| Person1 | Jai | 27 | Delhi | Msc |
| Person2 | Princi | 24 | Kanpur | MA |
| Person3 | Gaurav | 22 | Allahabad | MCA |
| Person4 | Anuj | 32 | Kannauj | Phd |
حال اگر بخواهیم سطر اول را انتخاب کنیم، با یکی از دو دستور زیر این کار را میتوانیم انجام دهیم:
#with locdf.loc[['Person1']]#with ilocdf.iloc[[0]]که خروجی هر دو کد یکسان است:
| Name | Age | Address | Qualification | |
|---|---|---|---|---|
| Person1 | Jai | 27 | Delhi | Msc |
نکته:
- یادآوری میکنیم که iloc تنها با اندیسهای عددی کار میکند و متد loc با اندیس تعریف شده در جدول.
- به دو جفت براکت کنار هر متد دقت کنید: اگر تنها یک جفت براکت بگذاریم خروجی به شکل ستونی زیر چاپ میشود:
Name Jai Age 27 Address Delhi Qualification Msc Name: Person1, dtype: objectاگر بخواهیم دو سطر اول و دوم را انتخاب کنیم مانند کد زیر عمل میکنیم:
#with locdf.loc['Person1':'Person2']#ordf.loc[['Person1','Person2']]#with ilocdf.iloc[0:2]| Name | Age | Address | Qualification | |
|---|---|---|---|---|
| Person1 | Jai | 27 | Delhi | Msc |
| Person2 | Princi | 24 | Kanpur | MA |
و برای انتخاب سطر اول و اول و ستون دوم و سوم:
#with locdf.loc['Person1':'Person2','Age':'Address']#ordf.loc[['Person1','Person2'],['Age','Address']]#with ilocdf.iloc[0:2,1:3]| Age | Address | |
|---|---|---|
| Person1 | 27 | Delhi |
| Person2 | 24 | Kanpur |
نکته: اگر ایندکس سطرها به صورت عددی بود، loc را مانند iloc مینویسیم با این تفاوت که در loc عدد اندیس آخر را درنظر میگیریم. یعنی مثلاً برای انتخاب سطر اول و دوم دستور را به صورت [loc[0:1 مینویسیم، درحالی که برای iloc به شکل [0:2]iloc است.
دسترسی به دیتافریم (Dataframe) با اندیسدهی بولین
برای دسترسی به دیتافریم (Dataframe) با اندیس بولین، باید دیتافریمها (Dataframe) را با اندیس بولین ایجاد کنیم. یعنی دیتافریمی (Dataframe) با اندیسهایی که مقادیر آن True یا False باشد. به طور مثال:
# importing pandas as pd import pandas as pd # dictionary of lists dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"], 'degree': ["MBA", "BCA", "M.Tech", "MBA"], 'score':[90, 40, 80, 98]} df = pd.DataFrame(dict, index = [True, False, True, False]) print(df) شکل این دیتافریم (Dataframe) به صورت زیر است:
name degree scoreTrue aparna MBA 90False pankaj BCA 40True sudhir M.Tech 80False Geeku MBA 98دسترسی به عناصر دیتافریم (Dataframe) با اندیس بولین همچون سایر دیتافریمها (Dataframe) به یکی از روشهای loc و iloc است. برای دسترسی با loc مقدار True یا False را به عنوان پارامتر ورودی ارسال میکنیم.
# importing pandas as pd import pandas as pd # dictionary of lists dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"], 'degree': ["MBA", "BCA", "M.Tech", "MBA"], 'score':[90, 40, 80, 98]} # creating a dataframe with boolean index df = pd.DataFrame(dict, index = [True, False, True, False]) # accessing a dataframe using .loc[] function print(df.loc[True]) name degree scoreTrue aparna MBA 90True sudhir M.Tech 80همانطور که قبلاً گفته شد، iloc تنها مقادیر عددی را به عنوان پارامتر ورودی میپذیرد، پس در نتیجه مقدار Boolean را نمیتوان به آن داد.
دسترسی به عناصر دیتافریم (Dataframe) با اپراتورهای منطقی روی ستونها وسطرها
میتوان برای دسترسی به عناصر برمبنای مقادیرشان به کمک اپراتورهای منطقی همچون ==، <=، >= و != فیلترهایی تعریف کرد. خروجی چنین فیلترهایی مجموعهای بولین با مقادیر True و False است.
# importing pandas as pd import pandas as pd # dictionary of lists dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"], 'degree': ["BCA", "BCA", "M.Tech", "BCA"], 'score':[90, 40, 80, 98]} # creating a dataframe df = pd.DataFrame(dict) # using a comparsion operator for filtering of data print(df['degree'] == 'BCA') 0 True1 True2 False3 TrueName: degree, dtype: boolهمین فیلترها را بر روی index یا همان برچسب سطرها نیز میتوان اعمال کرد. مثال زیر را در نظر بگیرید:
# importing pandas as pd import pandas as pd # dictionary of lists dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"], 'degree': ["BCA", "BCA", "M.Tech", "BCA"], 'score':[90, 40, 80, 98]} df = pd.DataFrame(dict, index = [0, 1, 2, 3])print(df[df.index>=2])name degree score2 sudhir M.Tech 803 Geeku BCA 98
مرتبسازی عناصر دیتافریم (Dataframe) در کتابخانه Pandas
برای مرتبسازی صعودی یا نزولی دادههای ستونهای دیتافریم (Dataframe) از تابع sort_values() استفاده میکنیم. قاعدهی کلی به شکل زیر است:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’)
تمامی پارامترها به جز by دارای مقادیر پیشفرضاند.
by: نام یک یا مجموعهای از ستونها برای مرتبسازی دادهها بر مبنای آن ستونها است.
axis: عدد 0 یا عبارت 'index' برای سطر و 1 یا 'columns' برای ستون.
ascending: یک مقدار بولین که اگر True بود صعودی، و اگر False بود نزولی مرتب میکند.
inplace: یک مقدار بولین است. اگر True بود در دیتافریم (Dataframe) انتقالی به تابع، تغییراتی ایجاد میکند.
kind: یک مقدار رشتهای است که میتواند سه مقدار 'quicksort'، 'mergesort' و یا 'heapsort' را بگیرد و الگوریتم مرتبسازی بر اساس آن عمل کند.
na_position: میتواند یکی از دو مقدار رشتهای 'last' یا 'first' را بگیرد و بر اساس آن تعیین کند که مکان مقادیر NAN یا همان تهی، پس از مرتبسازی در ابتدای جدول قرار گیرد یا در انتهای آن.
دیتافریم (Dataframe) برگشت داده شده از تابع مرتبسازی، همان ابعاد و shape دیتافریم (Dataframe) اولیه را دارد. فرض کنید دیتافریمی (Dataframe) با نام data به شکل زیر داریم و میخواهیم براساس ستون name سطرها را مرتب کنیم.
| name | Age | |
|---|---|---|
| 0 | John | 25 |
| 1 | Smith | 30 |
| 2 | Paul | 50 |
| 3 | Adam | 26 |
| 4 | Smith | 11 |
# importing pandas package import pandas as pd # sorting data frame by name data.sort_values("name", axis = 0, ascending = True, inplace = True, na_position ='last') # display data | name | Age | |
|---|---|---|
| 3 | Adam | 26 |
| 0 | John | 25 |
| 2 | Paul | 50 |
| 1 | Smith | 30 |
| 4 | Smith | 11 |
کار با مقادیر ناموجود یا تهی در دیتافریم (Dataframe)
دادهی ناموجود یا تهی (Missing Values) زمانی رخ میدهد که یک یا چند آیتم مقداردهی نشده باشند و یا اطلاعاتی در خصوص آنها در دست نباشد. دادهی ناموجود در تحلیل دادههای سناریوهای واقعی مسألهی مهمی است. در پانداس از آن تحت عنوان NA NotAvailible نیز یاد میشود.
کنترل مقادیر ناموجود با is null و not null
برای کنترل مقادیر ناموجود در دیتافریم (Dataframe) کتابخانه pandas (پانداس) میتوانیم از is null و not null استفاده کنیم. هردو تابع در کنترل اینکه آیا مقدار یک آیتم NAN هست یا نه؛ کمک میکنند. این توابع در سریها هم میتوانند برای یافتن مقادیر NAN به کار گرفته شوند. خروجی این توابع مقادیر بولین است.
# importing pandas as pdimport pandas as pd# importing numpy as npimport numpy as np# dictionary of listsdict = {'First Score':[100, 90, np.nan, 95], 'Second Score': [30, 45, 56, np.nan], 'Third Score':[np.nan, 40, 80, 98]}# creating a dataframe from listdf = pd.DataFrame(dict)# using isnull() function df.isnull()| First Score | Second Score | Third Score | |
|---|---|---|---|
| 0 | False | False | True |
| 1 | False | False | False |
| 2 | True | False | False |
| 3 | False | True | False |
مقداردهی مقادیر ناموجود با fillna، replace و interpolate
به منظور پرکردن و مقداردهی مقادیر تهی در دیتابیس از توابع fllna، replace و interpolate استفاده میکنیم که این توابع مقادیر NAN را با مقادیر تولیدی خود جایگزین میکنند. در کد زیر به کمک متد fillna مقادیر تهی را با صفر جایگزین میکنیم.
# importing pandas as pdimport pandas as pd# importing numpy as npimport numpy as np# dictionary of listsdict = {'First Score':[100, 90, np.nan, 95], 'Second Score': [30, 45, 56, np.nan], 'Third Score':[np.nan, 40, 80, 98]}# creating a dataframe from dictionarydf = pd.DataFrame(dict)# filling missing value using fillna() df.fillna(0)| First Score | Second Score | Third Score | |
|---|---|---|---|
| 0 | 100.0 | 30.0 | 0.0 |
| 1 | 90.0 | 45.0 | 40.0 |
| 2 | 0.0 | 56.0 | 80.0 |
| 3 | 95.0 | 0.0 | 98.0 |
حذف مقادیر null با تابع dropna
به منظور حذف مقادیر NAN از دیتافریم (Dataframe) از تابع dropna استفاده میکنیم. این تابع سطرها و ستونهای NAN را با شیوههای مختلف حذف میکند. دیتافریم (Dataframe) df را به شکل زیر داریم:
# importing pandas as pdimport pandas as pd# importing numpy as npimport numpy as np# dictionary of listsdict = {'First Score':[100, 90, np.nan, 95], 'Second Score': [30, np.nan, 45, 56], 'Third Score':[52, 40, 80, 98], 'Fourth Score':[np.nan, np.nan, np.nan, 65]}# creating a dataframe from dictionarydf = pd.DataFrame(dict)df| First Score | Second Score | Third Score | Fourth Score | |
|---|---|---|---|---|
| 0 | 100.0 | 30.0 | 52 | NaN |
| 1 | 90.0 | NaN | 40 | NaN |
| 2 | NaN | 45.0 | 80 | NaN |
| 3 | 95.0 | 56.0 | 98 | 65.0 |
در کد زیر سطرهایی که حداقل یک مقدار NAN دارند را حذف میکند.
# importing pandas as pdimport pandas as pd# importing numpy as npimport numpy as np# dictionary of listsdict = {'First Score':[100, 90, np.nan, 95], 'Second Score': [30, np.nan, 45, 56], 'Third Score':[52, 40, 80, 98], 'Fourth Score':[np.nan, np.nan, np.nan, 65]}# creating a dataframe from dictionarydf = pd.DataFrame(dict)# using dropna() function df.dropna()خروجی به شکل زیر خواهد بود:
| First Score | Second Score | Third Score | Fourth Score | |
|---|---|---|---|---|
| 3 | 95.0 | 56.0 | 98 | 65.0 |
حال کدی مینویسیم که با آن سطری را که همهی عناصر آن صفر باشد را حذف کنیم. فرض کنید دیتافریم (Dataframe) زیر را داریم که سطر دوم آن همگی NAN است:
# importing pandas as pd import pandas as pd # importing numpy as np import numpy as np # dictionary of lists dict = {'First Score':[100, np.nan, np.nan, 95], 'Second Score': [30, np.nan, 45, 56], 'Third Score':[52, np.nan, 80, 98], 'Fourth Score':[np.nan, np.nan, np.nan, 65]} df = pd.DataFrame(dict) # using dropna() function df.dropna(how = 'all')خروجی حاصل به شکل زیر است:
| First Score | Second Score | Third Score | Fourth Score | |
|---|---|---|---|---|
| 0 | 100.0 | 30.0 | 52.0 | NaN |
| 2 | NaN | 45.0 | 80.0 | NaN |
| 3 | 95.0 | 56.0 | 98.0 | 65.0 |
حذف ستونی با حداقل یک مقدار null
مجموعه دادهی زیر را در نظر بگیرید:
# importing pandas as pd import pandas as pd # importing numpy as np import numpy as np # dictionary of lists dict = {'First Score':[100, np.nan, np.nan, 95], 'Second Score': [30, np.nan, 45, 56], 'Third Score':[52, np.nan, 80, 98], 'Fourth Score':[60, 67, 68, 65]} # creating a dataframe from dictionary df = pd.DataFrame(dict) df| First Score | Second Score | Third Score | Fourth Score | |
|---|---|---|---|---|
| 0 | 100.0 | 30.0 | 52.0 | 60 |
| 1 | NaN | NaN | NaN | 67 |
| 2 | NaN | 45.0 | 80.0 | 68 |
| 3 | 95.0 | 56.0 | 98.0 | 65 |
دستور( dropna(axis=1 منجر به حذف ستونهای اول و دوم وسوم خواهد شد. (وقتی axis را برابر 1 قرار میدهیم یعنی متد روی ستونها کار میکند و اگر صفر باشد روی سطرها):
# importing pandas as pd import pandas as pd # importing numpy as np import numpy as np # dictionary of lists dict = {'First Score':[100, np.nan, np.nan, 95], 'Second Score': [30, np.nan, 45, 56], 'Third Score':[52, np.nan, 80, 98], 'Fourth Score':[60, 67, 68, 65]} # creating a dataframe from dictionary df = pd.DataFrame(dict) # using dropna() function df.dropna(axis = 1)| Fourth Score | |
|---|---|
| 0 | 60 |
| 1 | 67 |
| 2 | 68 |
| 3 | 65 |
جمعبندی:
در این مقاله به معرفی کتابخانه Pandas در پایتون پرداختیم. پانداس یک کتابخانهی متن باز است که برای کار بر روی دادههای برچسبدار و رابطهای طراحی شده است. چنین ساختار دادهای باعث میشود تا به کمک عملیات تعریف شده بر روی دادههای رابطهای تحلیل سودمندی روی دادهها انجام داد. این کتابخانه به خاطر قابلیت سرعت و قدرت خوب پردازشی در علم داده بسیار پرکاربرد است و توابع و متدهای فراوانی را فراهم کردهاست. با مطالعهی این مقاله و انجام مثالهای آن با این فریم ورک آشنا شده و قادر به شروع انجام پروژهی خود خواهید بود.
